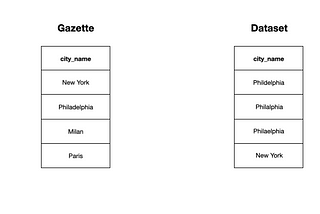
Enrico AlemaniGazetteer deduplication in PandasGazetteer deduplication is for matching a messy data set against a ‘canonical’ dataset (i.e. gazette). The former contains misspellings…Dec 19, 2020Dec 19, 2020
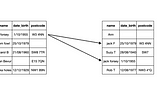
Enrico AlemaniRecord linkage in PandasRecord linkage is the process of linking records from different data sources (e.g. pandas dataframes) using any fields in common between…Dec 15, 20201Dec 15, 20201
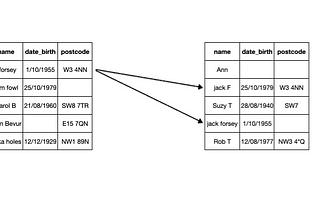
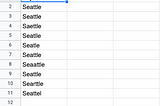
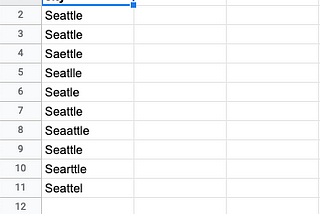
Enrico AlemaniRecords deduplication in PandasHow many times have you found yourself in a situation where you had to deal messy data, especially reconciliate mispellings, short forms…Nov 20, 2020Nov 20, 2020
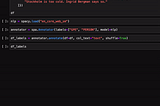
Enrico AlemaniFlatten nested dictionaries in pandas using glomPandas is great! You can do pretty much eveything with it: from data cleaning to quick data viz. How about working with nested dictionary…Jun 23, 2020Jun 23, 2020
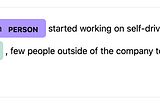
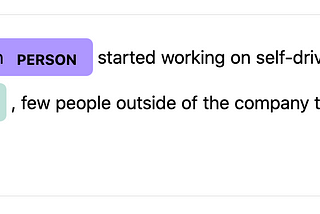
Enrico AlemaniThe customized spaCy training loopCustomization and implementation of tips and advice for NER trainingMay 10, 20201May 10, 20201
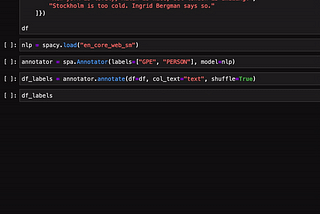
Enrico AlemaniHow to create training data for spaCy NER models using ipywidgetsIn this post, I present the spacy-annotator: a library to create training data for the spaCy Named Entity Recognition (NER) model using…May 3, 20202May 3, 20202
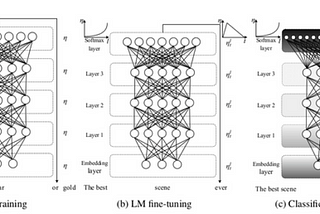
Enrico AlemaniFake reviews detection and transfer learningWe apply the Universal Language Model Fine-Tuning(ULMFiT) by Howard and Ruder (2018) to fake reviews detection and demonstrate that deep…Jan 4, 2020Jan 4, 2020